TL;DR
I found the longest n-gram on Wikipedia which appears more than 1,000 times. It is 103 words long. It is:
The township is governed by a three-member board of trustees, who are elected in November of odd-numbered years to a four-year term beginning on the following January 1. Two are elected in the year after the presidential election and one is elected in the year before it. There is also an elected township fiscal officer, who serves a four-year term beginning on April 1 of the year after the election, which is held in November of the year before the presidential election. Vacancies in the fiscal officership or on the board of trustees are filled by the remaining trustees.It appears 1,275 times (exactly, word-for-word), only in articles about small towns in Ohio. It’s part of the Ohio Revised Code which as far as I can tell applies to all Ohioan townships.
What is an n-gram?
An n-gram is a sequence of words which appears often in a text, or in a corpus of texts. Finding these is helpful for document classification as repeated sequences of words often have a meaning different than their individual words would suggest. An “Academy Award” isn’t just an award from an academy, but a specific award from the Academy of Motion Picture Arts and Sciences. Letting our models know during training that “Academy Award” may mean something different than “academy” and “award” can make it easier to identify fine-grained topics like this.
How I found this
After cleaning my Wikipedia corpus, I took several additional steps to normalize it:
- I made everything lowercase
- Sequences of numbers became “
_num_“ - A “
_num_” followed by a percent symbol is replaced with “_percent_“ - Certain recognized date formats become “
_date_“, for example “10 January 1995“
That is, for the purposes of my analysis I consider numbers to be “semantically identical”. The phrase “he was 29 years old” doesn’t have a significantly different meaning from “he was 81 years old”. For first-pass machine learning models the noise and variance introduced by treating every number as a completely different “word” is rarely useful.
Beyond the above, I define a “word” to be any sequence of characters matching the regex “[\w']+“, and I define words to be “distinct” if, and only if their lowercase forms exactly match.
To find the n-grams, I employed an iterative algorithm which takes as input all currently-known n-grams. On first iteration it only finds all 2-grams. The second iteration, it finds all 3-4-grams. Each iteration, the maximum n-gram length it finds doubles. You can find the successive commands I ran to do this in my GitHub repository.
Other long n-grams
The longest n-gram appearing more than 10,000 times is:
There were _num_ households out of which _percent_ had children under the age of _num_ living with them, _percent_ were married couples living together, _percent_ had a female householder with no husband present, and _percent_ were non families. _percent_ of all households were made up of individuals and _percent_ had someone living alone who was _num_ years of age or older. The average household size was _num_ and the average family size was _num_.The longest (and most-frequent) n-gram appearing more than 100,000 times is:
from _num_ to _num_which is recognizable as a range of numbers expressed in natural language.
I mean, technically it’s “_num_ _num_ _num_ _num_” because sequences of numbers appear so often, but I don’t like it since it doesn’t have any “real words”.
The longest n-gram appearing more than 100,000 times which only contains alphabetic words is “a member of the“. Most n-grams of this length serve common structural purposes such as this.
In general, the most common n-grams of length longer than 5 are from templates, where article content has been imported from another source, or where it is very clear that the same author uses identical language in a long list of articles. For example:
4,966: ... is a moth in the family Crambidae it was described by ...
3,935: In the CDP the population was spread out, with _percent_ under the age of _num_ _percent_ ...
4,907: ... together _percent_ had a female householder with no ...
4,003: ... is a protein that in humans is encoded by the ...Charts
I made graphs of the longest n-gram of a given frequency. I’ve dropped lengths for n-grams which appeared less often than longer n-grams. This first graph includes the special handling I use for numbers, dates, and percentages.

This second graph is for the “more traditional” n-grams which only include alphabetic words.

Conclusion
This is going to let me get rid of a lot of noise when I begin training models on the Wikipedia corpus. In this case, looking for n-grams allowed me to find a lot of duplicated, stilted, not-really-human language which would have messed up my model’s ability to understand how words are used.
Rather than consider all uses of words like “elected” as the same, I can consider it a special case when it appears in the 103-word monstrosity I mentioned at the beginning. Models are sensitive to frequency, and lots of cases of a word being used in an identical context incorrectly teaches the model that this is common or expected. In reality, a human composed the passage once, and it was likely automatically duplicated (or manually copy+pasted) over a thousand times. There isn’t much to be learned from such usage. Instead, for cases like this the 103-word n-gram provides strong evidence that an article is about a very specific type of thing – a township in Iowa, which is exactly what I want my model to learn from this.
On a smaller scale, being able to treat n-grams like “the United States” as entities distinct from words like “states” and “united” means that the model won’t be tricked into confusing “United Airlines” or “States Records” with “the United States”.
This is the sort of analysis it is almost always worth doing on a corpus – while going through this work I iterated dozens of times on the code I used to clean the corpus, as each time I found cases where there were bits of formatting or common human mistakes that caused this analysis to give strange results. Now that I can get results like this, I can be confident that overall my data is clean enough for more complex work.


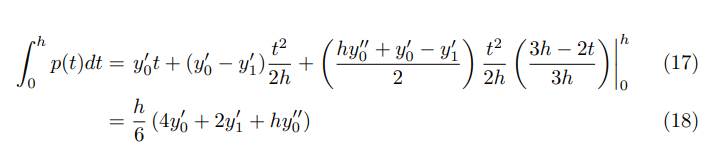
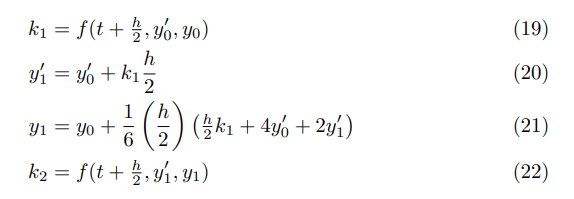
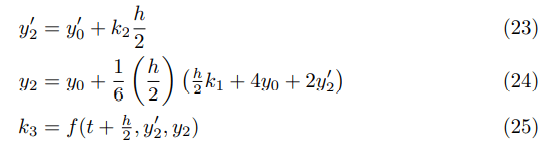
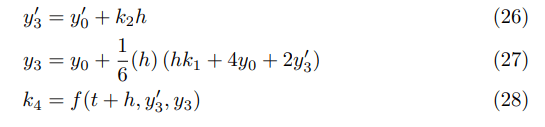
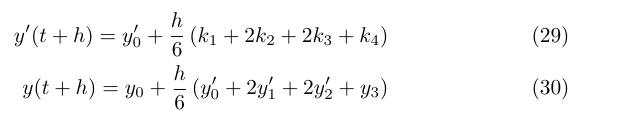



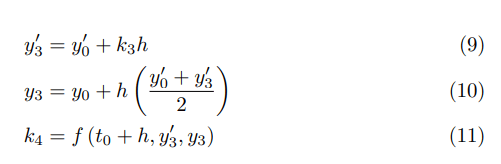





{kind=link}